
Cette formation se décompose en deux parties, tout d’abord un guide de démarrage rapide permettant d’être rapidement capable d’utiliser git mais seulement les rudiments. Et une autre partie présentant de manière plus complète et posée le fonctionnement d’un système de versionnage des fichiers. Les deux parties sont totalement indépendantes et ne dépendent que du temps et des compétences voulus du lecteur. Lien direct vers la partie 2
L’apprentissage de git par un document écrit ne remplacera jamais la maîtrise via la pratique. Quelques applications comme Git commands - Best for the beginners sur android ou cette page permettent de completer ce document.
Support de présentation
Rediffusion de la formation
Partie 1 - Généralités (clone, add, commit, push, pull)
Partie 2 - Conflit , branche et rebase
Guide de démarrage rapide (et incomplet !)
Github, qu’est ce que c’est ?
Github est un service en ligne qui permet d’héberger ses repositories de code. Github est un outil gratuit pour héberger du code open source. Pour commencer à utiliser Github il faut créer son compte sur la page page d’acceuil, rentrer son nom d’utilisateur , un mot de passe etc. Une fois cela fait, il faut penser à communiquer son pseudo pour pouvoir accéder au dossier d’eirbot
Sur Linux il suffit d’avoir un terminal pour faire toutes les commandes git. En revanche si vous êtes sur Windows…tant pis 1
Récupérer du code d’un autre d’un autre repository
Une fois le compte Github créé, du code d’un autre
repository peut être récupéré. Pour cela il faut cloner le répertoire,
il suffit de cliquer sur clone sur Github et de copier le lien en https. (On
pourra modifier pour pouvoir utiliser le ssh plus tard).
Une fois le lien copié on tape dans un bash la commande suivante
git clone https://github.com/eirbot/eirbot2020-1A.git
Cela permet de créér une copie locale du dossier sur notre machine.
Envoyer du code sur Github
Maintenant qu’une copie locale du dossier existe sur la machine, le code (ou
n’importe quel fichier) peut être modifié de manière locale. Lorsque le travail
terminé il faut synchroniser les modifications effectuées sur le repository
local avec le repository distant. L’opération que nous allons décrire permet de valider un
ensemble de modifications dans le code pour créer une nouvelle révision, et est
communément appelé un commit.
Commençons par visualiser l’état des fichiers dans le dépôt avec la commande suivante 2
git status
Si le fichier n’a jamais été communiqué au dépôt, le résultat devrait être être de la forme
Untracked files:
(use "git add <file>..." to include in what will be committed)
nom_du_fichier
Si le fichier était déjà présent dans le dépôt, le résultat devrait être de la forme :
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: nom_du_fichier
Une fois que nous connaissons l’état des fichiers il faut choisir ceux que l’on veut envoyer pour cela
git add nom_du_fichier
Une fois les fichiers ajouté nous pouvons commit ces derniers via
git commit
Cela va ouvrir un éditeur de texte, il faut ajouter un commentaire. Une fois le commentaire validé la révision a été créé.
Attention ! Les commentaires des commits sont les premières choses que les collaborateurs vont voir, un commit comme ``pause dej’’ n’a aucun intéret3, les collaborateurs ne peuvent pas comprendre ce que vous avez fait. Il est donc conseillé de commit fichier par fichier en expliquant correctement les modifications réalisées sur chaque fichier.
Comme il s’agit d’une modification des sources, il faut la communiquer au dépôt distant. Le dépôt distant se nomme par défaut origin, et la branche à communiquer master. Communiquer votre modification des sources avec la commande suivante :
git push origin master
Récupérer des modifications
Pour récupérer en local les dernières modifications du repository Github, il faut utiliser la commande la commande
git pull origin master
Lorsque l’on réalise un git pull on effectue un fetch puis
un merge. Dans nos conditions de travail, il est préférable de
réaliser un rebase pour que cela soit automatique il faut taper la commande
suivante.
git config --global branch.master.rebase true
Gérer un conflit sur du code
Du fait de la présence de multiples dépôts dans lesquels le code peut être modifié, il est possible que la même branche master ait divergé entre deux dépôts (typiquement avec la même branche sur un dépôt distant, comme origin/master). Dans ce cas, une fusion/merge risque d’amener à un conflit. Il convient de ne surtout pas paniquer, cela fait partie des tracas standards du développement logiciel. Mettons que la dernière fusion/merge ait amené au résultat suivant :
Auto-merging nom_du_fichier
CONFLICT (content): Merge conflict in nom_du_fichier
Automatic merge failed; fix conflicts and then commit the result.
Il faut bien noter que l’opération de fusion/merge ne s’est pas terminée (“no changes added to commit”). Git vous met dans un état où il est possible de l’assister à terminer cette fusion correctement.
Pour chaque fichier en conflit, appliquer la procédure suivante :
- Ouvrir le fichier dans un éditeur (dans notre exemple nom_du_fichier).
- Rechercher dans l’éditeur les blocs de la forme suivante :
<<<<<< HEAD Teddy , le programmeur extremiste. ======= Teddy , le programmeur extreme. >>>>>> origin/master
Git a modifié de lui-même le fichier pour inclure, aux endroits qui lui
semblaient différents, les deux versions. Il est facile de rechercher ces blocs
car les marqueurs <<<<<<<, ======= et >>>>>>> ne sont quasiment jamais utilisés.
La zone délimitée par <<<<<<< et ======= représente la version locale du
code (branche master).
La zone délimitée par ======= et >>>>>>> représente la
version distante du code (branche origin/master). Modifier le code de manière à
éliminer tous les marqueurs. Il est ainsi facile de choisir une version des deux
versions à garder, ou de faire une sorte de mélange des deux si besoin.
3. A la fin des modifications, ajouter le code au commit (ici le fichier en conflit)
git add nom_du_fichier
- Une fois tous les fichiers en conflit gérés, terminer la fusion (un message de commit est généré automatiquement) :
git commit
Authentification via clé SSH
Si vous voulez utilisez cloner quelque chose des dépôts distants, vous devrez choisir entre un des deux moyens : HTTPS ou SSH. Si vous utilisez HTTPS, vous devrez taper l’accès de votre compte chaque fois pour communiquer avec le dépôt distant, il y a un moyen de contourner le problème, la méthode d’authentification SSH.
Pour modifier son authentification vers ssh il faut tout d’abbord générer une clé privée et une clé publique sur le poste client.
ssh-keygen -t rsa -b 4096 -C ``[your github's email]''
Ensuite lorsque le terminal affiche ce texte appuyez sur Entrer
> Entrez un fichier dans lequel enregistrer la clé\\
(/Users/you/.ssh/id\_rsa): [Appuyez sur Entrer]
Finalement il faut définir un mot de passe associé à cette clé
> Entrez la phrase secrète (vide pour ne pas utiliser de phrase secrète): [Tapez une phrase secrète] \\
> Entrez à nouveau la même phrase secrète: [Tapez à nouveau la phrase secrète]
Voyons maintenant comment ajouter la clé SSH à ssh-agent. Tout d’abbord assurez vous que ssh-agent est activé
``` shell
eval "$(ssh-agent -s)"
```
A finir
Gérez vos codes sources avec Git
Qu’est ce qu’un logiciel de gestion de version ?
Les logiciels de gestion de versions sont utilisés principalement par les développeurs. En effet ils sont quasi exclusivement utilisés pour gérer des codes sources car ils sont capables de suivre l’évolution d’un fichier texte ligne de code par ligne de code. Ces logiciels sont fortement conseillées pour gérer un projet informatique. Ces outils suivent l’évolution de vos fichiers source et gardent les anciennes versions de chacun d’eux. S’ils s’arrêtaient à cela, ce ne seraient que de vulgaire outils de backup. Cependant, ils proposent de nombreuses fonctionnalités qui vont vraiment vous être utiles tout au long de l’évolution de votre projet informatique
- ils retiennent qui à effectué chaque modification de chaque fichier et pourquoi. Ils sont par conséquent capables de dire qui a écrit chaque ligne de code de chaque fichier et dans quel but
- si deux personnes travaillent simultanément sur un même fichier, ils sont capables d’assembler (de fusionner) leurs modifications et d’éviter que le travail d’une de ces personnes ne soit écrasé
Ces logiciels ont donc par conséquent deux utilités principales
- suivre l’évolution d’un code source, pour retenir les modifications effectués sur chaque fichier et ainsi capable de revenir en arrière en cas de problème
- travailler à plusieurs, sans risquer de se marcher sur les pieds. Si deux personnes modifient un même fichier en même temps, leurs modifications doivent pouvoir être fusionnées sans perte d’information
Logiciels centralisés et distribués
Il existe deux types principaux de logiciels de gestion de versions
- Les logiciels centralisés : un serveur conserve les anciennes versions des fichiers et les développeurs s’y connectent pour prendre connaissance des fichiers qui ont été modifiés par d’autres personnes et pour y envoyer leurs modifications
- Les logiciels distribués : il n’y a pas de serveur, chacun possède l’historique de l’évolution de chacun des fichiers. Les développeurs se transmettent directement entre eux les modifications.
C’est dans ce dernier mode que nous allons fonctionner avec Git. Il a l’avantage d’être à la fois flexible et pratique. Pas besoin de faire de sauvegarde du serveur étant donné que tout le monde possède l’historique des fichiers, et le serveur simplifie la transmission des modifications.
Installer et configurer Git
Installation.
Nous allons voir ici comment installer Git sous Linux, Windows et Mac OS X. Git est plus agréable à utiliser sous Linux et sensiblement plus rapidement, mais il reste néanmoins utilisable sous Windows.
Installer Git sous Linux.
Avec le gestionnaire de paquet sudo apt install git-core gitk. Le premier paquet contient git en tant que tel, gitk est une interface graphique qui aide à mieux visualiser les logs, elle est facultative.
Installer Git sous Windows.
Pour utiliser Git sous Windows, il faut installer myssgit. Cela installer msys et Git simultanément. Un logiciel comme GitHub Desktop peut tout à fait convenir aussi.
Lors de l’installation, laissez toutes les options par défaut, elles conviennent bien. Une fois que c’est installé, vous pouvez lancer une console qui permet d’utiliser Git en ouvrant l programme Git Bash. Les commandes de base d’Unix fonctionnent sans problème.
Installer Git sous Mac Os X
Le plus simple est d’installer cet installeur pour Mac OS X. Vous allez télécharger une archive .dmg. Il suffit de l’ouvrir pour la monter, ce qui vous donner accès à plusieurs fichiers. Ouvrez tout simplement l’archive .pkg qui se trouve à l’intérieur, ce qui aura pour effet d’exécuter le programme d’installation. Suivez les étapes en laissant les valeurs par défaut.
Configurer Git
Maintenant que Git est installé, vous devriez avoir une console ouverte dans laquelle vous allez pouvoir taper des commandes de Git. Dans la console, commencez par envoyer ces trois lignes
git config --global colof.diff auto
git config --global color.status auto
git config --gloabl color.branch auto
Elle activeront la couleur dans Git. Il ne faut le faire qu’une fois, cela aide à la lisibilité des messages dans la console. De même il faut configurer votre nom et votre email
git config --global user.name "your name"
git config --global user.email your@email.com
Vous pouvez aussi éditer votre fichier de configuration .gitconfig situé dans votre répertoire personnelle pour y ajouter une section alias à la fin. Ces alias permettent de raccourcir certaines commandes de Git. Ainsi, au lieu d’écrire git checkout, vous pourrez écrire si vous le désirez git co, ce qui est plus cours
[color]
diff = auto
status = auto
branch = auto
[user]
name = votre_pseudo
email = moi@email.com
[alias]
ci = commit
co = checkout
st = status
br = branch
Créer un nouveau dépôt ou cloner un dépôt existant
Pour commencer à travailler avec Git, il y a deux solutions
- soit vous créez un nouveau dépôt vide, si vous souhaitez commencer un nouveau projet
- soit vous clonez un dépôt existant, c’est à dire que vous récupérez tout l’historique des changements d’un projet pour pouvoir travailler dessus
Cloner un dépôt existant consiste à récupérer tout l’historique et tous les codes source d’un projet avec Git. Pour trouver un dépôt Git vous pouvez vous rendre sur la page Github du projet à cloner et copier le lien qui s’affiche derrière le bouton “clone”. Pour cloner le dépôt il suffit de lancer la commande suivante
git clone url
Cela va créer un dossier et y télécharger tous les fichiers source du projet ainsi que l’historique de chacune de leurs modifications. Git compresse automatiquement les données pour le transfert et le stockage afin de ne pas prendre trop de place. Néanmoins, le clonage d’un dépôt comme ceci peut prendre beaucoup de temps.
Modifier le code et effectuer des commits
A ce stade, vous devriez savoir créer un clone un dépôt Git. Supposons que vous ayez cloné le dépôt Git eirbot2020-1A. Vous avez sur votre disque dur tous les fichiers source du projet et vous pouvez vous amuser à les modifier avec un éditeur de texte. Une fois cela fait placez vous dans le répertoire du code et effectuez la commande git status. Cette dernière va vous permettre de voir les changements que vous avez effectué sur le projet.
Méthode de travail
Lorsqu’on travaille avec Git, on suit en général toujours les étapes suivantes
- modifier le code source
- tester votre programme pour vérifier si cela fonctionne
- faire un commit pour enregistrer les changements et les faire connaître à git
- recommencer à partir de l’étape 1 pour une autre modification
Qu’est ce qu’on appelle une modification du code source ?
C’est un ensemble de changements qui permet soit de régler un bug, soit d’ajouter une fonctionnalité
Cela peut aussi bien correspondre à une ligne changée dans un fichier que 50 lignes changées dans un fichier A et 25 lignes dans un fichier B. Un commit représente donc un ensemble de changement. A vous de déterminer, dès que vos changements sont stables, quand vous devez faire un commit. Notez bien que si vous travaillez toute une journée sur un code et que vous ne faites qu’un commit à la fin de la journée, c’est qu’il y a un problème. Les commits sont là pour “valider” l’avancement de votre projet : n’en faites pas un pour chaque ligne de code modifiée, mais n’attendez pas d’avoir fait 50 modifications différentes non plus.
Supposons que vous ayez effectué des modifications dans un des fichiers. Si vous avez modifié ce fichier et que vous l’avez enregistré, fait un git status dans la console pour voir
git status
# On branch master
# Changed but not updated:
# (use "git add <file>…" to update what will be committed)
# (use "git checkout -- <file>…" to discard changes in working directory)
#
# modified: src/navigation.cc
#
no changes added to commit (use "git add" and/or "git commit -a")
Git vous liste tous les fichiers qui ont changé sur le disque. Il peut aussi bien détecter les modifications que les ajouts, les suppressions et les renommages. Vous pouvez voir concrètement ce que vous avez changé en tapant git diff. Les lignes ajoutées sont précédées d’un “+” tandis que les lignes supprimées sont précédées d’un “-”. Normalement les lignes sont colorées et donc faciles à repérer.
Si les modifications vous paraissent bonnes et que vous les avez TESTEES, il est temps de fiare un commit.
Effectuer un commit des changements
En faisant git status vous devriez voir les fichiers que vous avez modifiés en rouge. Cela signifie qu’ils ne sont pas pris en compte lorsque vous allez faire un commit. Il faut explicitement préciser les fichiers que vous voulez commiter. Pour cela faites un git add nomfichier1 nomfichier2 ... pour ajouter à la liste de ceux devant l’objet d’un commit, puis faire git commit.
Il pourrait être tentant de réaliser un git commit -a pour ajouter tous les fichiers que vous avez modifié d’un coup. C’est une fausse bonne idée en effet lorsque vous faites cela, le commentaire que vous allez associer au commit ne pourra pas résumer tout ce que vous avez modifié, vos collaborateurs auront du mal à comprendre rapidement toutes vos modifications.
Lorsque la commande commit est lancée, l’éditeur par défaut s’ouvre. Vous devez sur la première taper un message qui décrit à quoi correspondent vos changements. Les lignes suivantes vous permettent de décrire plus en détail vos changements mais ne seront pas visibles au premier coup d’oeil par vos collaborateurs (elles sont tout de même très utile lorsque l’on veut comprendre plus en détail un commit).
Une fois le message de commit enregistré, Git va officiellement sauvegarder vos changements dans un commit. Il ajoute donc cela à la liste des changements qu’il connait du projet. Cependant pour l’instant votre commit est local, nous apprendrons à le mettre sur le serveur plus loin. Cela a un avantage, si vous vous rendez compte que vous avez fait une erreur dans votre dernier commit, vous avez la possibilité de l’annuler.
Annuler un commit effectué par erreur
Il est fréquent de chercher à comprendre ce qui s’est passé récemment, pourquoi une erreur a été introduite et comment annuler ce changement qui pose problème. C’est même là tout l’intérêt d’un logiciel de versions comme Git. Nous allons d’abord apprendre à lire les logs, puis nous verrons comment corriger une erreur.
Que s’est-il passé ? Vérifions les logs.
Il est possible à tout moment de consulter l’historique des commits : ce sont les logs. Vous pouvez ainsi retrouver tout ce qui a été changé depuis les débuts du projet. Lorsque vous avez effectué un commit, vous devriez voir dans git log
commit 227653fd243498495e4414218e0d4282eef3876e
Author: Fabien Potencier <fabien.potencier@gmail.com>
Date: Thu Jun 3 08:47:46 2010 +0200
[TwigBundle] added the javascript token parsers in the helper extension
commit 6261cc26693fa1697bcbbd671f18f4902bef07bc
Author: Jeremy Mikola <jmikola@gmail.com>
Date: Wed Jun 2 17:32:08 2010 -0400
Fixed bad examples in doctrine:generate:entities help output.
commit 12328a1bcbf231da8eaf942f8d68c7dc0c7c4f38
Author: Fabien Potencier <fabien.potencier@gmail.com>
Date: Thu Jun 3 08:42:22 2010 +0200
[TwigBundle] updated the bundle to work with the latest Twig version
Corriger un erreur.
Voici différentes méthodes permettant de corriger les erreurs, selon leur ancienneté ou leur importance.
- Modifier le dernier message de commit. Si vous avez fait une faute d’orthographe dans votre dernier message de commit ou que vous voulez tout simplement le modifier, vous pouvez le faire facilement grâce à la commande
git commit --amend. L’éditeur de texte s’ouvrira à nouveau pour changer le message. Cette commande est généralement utilisée juste après avoir effectué un commit lorsqu’on se rend compte d’une erreur dans le message. Il est en effet impossible de modifier le message d’un commit lorsque celui-ci a été transmis à d’autres personnes - Annuler le dernier commit. Si vous voulez annuler votre dernier commit
git reset numérooù numéro est l’identifiant du commit auquel on veut revenir. Seul le commit est retiré de Git, vos fichiers, eux restent modifiés. Vous pouvez alors à nouveau changer vos fichiers si besoin est et refaire un commit - Annuler tous les changements du dernier commit. C’est une assez mauvaise idée, il y a peu de cas d’utilisation la commande est
git reset --hard HEAD^ - Annuler les modifications d’un fichier avant un commit. Si vous avez modifié plusieurs fichiers mais que vous n’avez pas encore envoyé le commit et que vous voulez restaurer un fichier tel qu’il était au dernier commit, utilisez
git checkout nomfichier - Annuler/Supprimer un fichier avant un commit. Supposons que vous veniez d’ajouter un fichier à Git avec
git addet que vous vous apprétiez à commit. Cependant vous vous rendez compte que ce fichier est une mauvaise idée et vous voudriez annuler l’ajout, cela est possible en procédant comme suitgit reset HEAD -- fichier_a_supprimer
Télécharger les nouveautés et partager votre travail
Pour le moment, vous avez tout effectué en local. Comment partager votre travail avec d’autres personnes ?
Télécharger les nouveautés.
La commande git pull télécharge les nouveautés depuis le serveur. Deux cas sont possible
- soit vous n’avez effectué aucune modifications depuis le dernier pull, dans ce cas la mise à jour est simple
- soit vous avez fait des commits en même temps que d’autres personnes. Les changements qu’ils ont effectués sont alors fusionnés aux vôtres automatiquement.
Si deux personnes modifient en même temps deux endroits distincts d’un même fichier, les changements sont intelligemment fusionnés par Git.
Parfois, mais cela arrive normalement rarement, deux personnes modifient la même zone de code en même temps. Dans ce cas, Git dit qu’il y a un conflit car il ne peut décider quelle modification doit être conservée ; il vous indique alors le nom des fichiers en conflit. Ouvrez-les avec un éditeur et recherchez une ligne contenant « ««««< ». Ces symboles délimitent vos changements et ceux des autres personnes. Supprimez ces symboles et gardez uniquement les changements nécessaires, puis faites un nouveau commit pour enregistrer tout cela.
Envoyer vos commits.
Vous pouvez envoyer vos commits sur le serveur qui sert de point de rencontre entre les développeurs. Pour envoyer vos commits vous pouvez le faire avec la commande git push. Le changement vers le serveur ne peut pas donner lieu à des conflits puisque vous ne pouvez effectuer un push si quelqu’un d’autre à push après votre dernier pull.
Travailler avec des branches
Les branches font parti du coeur même de Git et constituent un de ses principaux atouts. C’est un moyen de travailller en parallèle sur d’autres fonctionnalités. C’est comme si vous aviez quelque part une copie du code source du site qui vous permet de tester vos idées et de vérifier si elles fonctionnent avvant de les intégrer au véritable code source de votre projet.
Dans git, toutes les modifications que vous faites au fil du temps sont pas défaut considérées comme appartenant à la branche principale appelée master. Supposons que vous ayez une idée pour améliorer la gestion des erreurs dans votre programme mais que vous ne soyer pas sûrs qu’elle va fonctionner : vous voulez faire des tests, ça va vous prendre du temps, donc vous ne voulez pas que votre projet incorpore ces changements dans l’immédiat. Il suffit de créer une branche, dans laquelle vous allez pouvoir travailler en parallèle
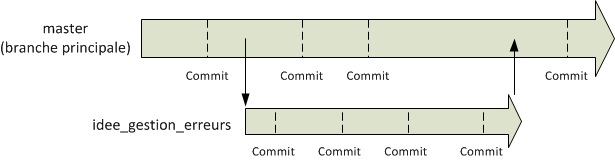
A un moment donné, nous avons décidé de créer une nouvelle branche. Nous avons pu y faire des commits, mais cela ne nous a pas empêché de continuer à travailler sur la branche principale et d’y faire des commits aussi. A la fin, mon idée s’est révélée concluante, j’ai donc intégré les changements dans la branche principale “master”. Mon projet dispose maintenant de mon idée que j’avais développée en parallèle. Tous les commits de ma branche se retrouvent fusionnés dans la branche principale.
Git n’est pas le seul outil capable de gérer des branches, mais il est le seul à le faire aussi bien, En effet, en temps normal vous pourriez tout simplement copier le répertoire de votre projet dans un autre dossier, tester les modifications et les incorporer ensuite dans le véritable dossier de votre projet. Mais cela aura nécessité de copier tous les fichiers et de se souvenir de tout ce que vous avez modifié. Cela inclut en plus des conflits dans le cas où quelqu’un aurait modifié le même fichier que vous en même temps dans la branche principale.
Git gère tous ces problèmes pour vous. Au lieu de créer une copie des fichiers, il crée juste une branche “virtuelle” dans laquelle il retient vos changements en parallèle. Lorsque vous décidez de fusionner une branche. Git vérifie si vos modifications n’entrent pas en conflit avec des commits effectués en parallèle. Si il y a des conflits, il essaie de les résoudre tout seul ou vous avertir s’il a besoin de votre avis.
Ce concept de branches très légères qui ne nécessitent pas de copier les fichiers est d’une grande puissance. Cela encourage à créer des branches tout le temps, pour les modifications qui pourraient prendre du temps avant d’être terminées. Vous pouvez même créer une sous branche à partir d’une branche.
Les branches locales.
Tout le monde commence avec une seule branche master : c’est la branche principale. Jusqu’ici, vous avez donc travaillé dans la branche “master”, sur le “vrai” code source de votre projet. Pour voir toutes vos branches, tapez git branch. Vous verrez normalement uniquement “master”. Il y a une étoile devant pour indiquer que c’est la branche sur laquelle vous êtes actuellement.
Pourquoi créer une branche et quand dois-je en créer une ?
Lorsque vous vous apprêtez à faire des modifications sur le code source, posez vous les questions suivantes
- Ma modification sera-t-elle rapide ?
- Ma modification est-elle simple ?
- Ma modification nécessite-t-elle un seul commit ?
- Est ce que je vois précisément comment faire ma modification d’un seul coup ?
Si la réponse à l’une de ces questions est non, vous devriez probablement créer une branche. Créer une branche est très simple, très rapide et très efficace. Il ne faut donc pas s’en priver.
Créer une branche et changer de branche
Supposons que vous vouliez créer une branche. Pour cela vous allez utiliser.
git branch <NAME>
Cela crée une branche appelée “NAME”. Il est important que pour l’instant cette branche est locale : vous seuls y avez accès. Une fois la branche créer vous pouvez vous déplacer dessus grâce à git checkout NAME.
Qu’est-ce qui se passe lorsque l’on change de branche ? En fait, vous ne changez pas de dossier sur votre disque dur, mais Git change vos fichiers pour qu’ils reflètent l’état de la branche dans laquelle vous vous rendez. Imaginez que les branches dans Git sont comme des dossiers virtuels : vous « sautez » de l’un à l’autre avec la commande git checkout . Vous restez dans le même dossier, mais Git modifie les fichiers qui ont changé entre la branche où vous étiez et celle où vous allez.
Faites maintenant des modifications sur les fichiers, puis un commit, puis d’autres modifications, puis un commit, etc. Si vous faites git log , vous verrez tous vos récents commits.
Maintenant, supposons qu’un bug important ait été détecté sur votre site et que vous deviez le régler immédiatement. Revenez sur la branche « master », branche principale du site en utilisant git checkout master. Faites vos modifications, un commit, éventuellement un push s’il faut publier les changements de suite etc. Ensuite revenez à votre branche git checkout NAME.
Fusionner les changements.
Lorsque vous avez fini de travailler sur une branche et que celle-ci est concluante, il faut “fusionner” cette branche vers “master”. Tout d’abord vous devez vous rendre sur la branche master via git checkout master, puis demander le merge de la branche NAME et master avec la commande git merge NAME. Tous vos commits de la branche NAME se retrouvent maintenant dans master.
Votre branche NAME ne servant plus à rien, vous pouvez donc la supprimer git branch -d NAME. Git vérifie que votre travail dans la branche NAME a bien été fusionné dans master. Sinon, il vous en avertit et vous interdit de supprimer la branche.
Ajouter ou supprimer une branche sur le serveur
Il est possible d’ajouter des branches sur le serveur pour y travailler à plusieurs, voici comment on ajoute une branche sur le serveur
git push origin NAME
-
L’utilisation de logiciel comme Git SCM permettra de réaliser toutes les actions après chacun peut utiliser son logiciel préféré, vive emacs ↩︎
-
Cette étape est assez pratique au début pour comprendre où l’on va, on s’en passe rapidement ↩︎
-
Cela a plutôt tendance à énerver vos collègues et les conduire à détruire chaqu’un de vos commits (oui oui c’est possible) ↩︎